安装Nginx
下载Nginx
$ cd /app/nginx $ Wget http://nginx.org/download/nginx-1.7.11.tar.gz编译Nginx
$ cd /app/nginx $ tar zvxf nginx-1.7.11.tar.gz $ cd nginx-1.7.11 $ .configure安装Nginx
$ make & make install
配置反向代理
修改配置文件
$ cd /usr/local/nginx $ vi ./conf/nginx.conf添加以下代码到server>location / 中
add_header 'Access-Control-Allow-Origin' '*'; add_header 'Access-Control-Allow-Credentials' 'true'; add_header 'Access-Control-Allow-Methods' 'GET'; proxy_pass http://192.168.55.64:8002/HDFSWeb/;- 保存配置
配置文件缓存
修改配置文件
$ cd /usr/local/nginx $ vi ./conf/nginx.conf添加以下代码到server 中
##cache## proxy_connect_timeout 5; proxy_read_timeout 60; proxy_send_timeout 5; proxy_buffer_size 16k; proxy_buffers 4 64k; proxy_busy_buffers_size 128k; proxy_temp_file_write_size 128k; proxy_temp_path /home/temp_dir; proxy_cache_path /home/cache levels=1:2 keys_zone=cache_one:200m inactive=1d max_size=30g; ##end##添加以下代码到server 中
proxy_redirect off; proxy_set_header Host $host; proxy_cache cache_one; proxy_cache_valid 200 302 1h; proxy_cache_valid 301 1d; proxy_cache_valid any 1m; expires 30d;保存配置
启动Nginx
$ /usr/local/nginx/sbin/nginx
测试
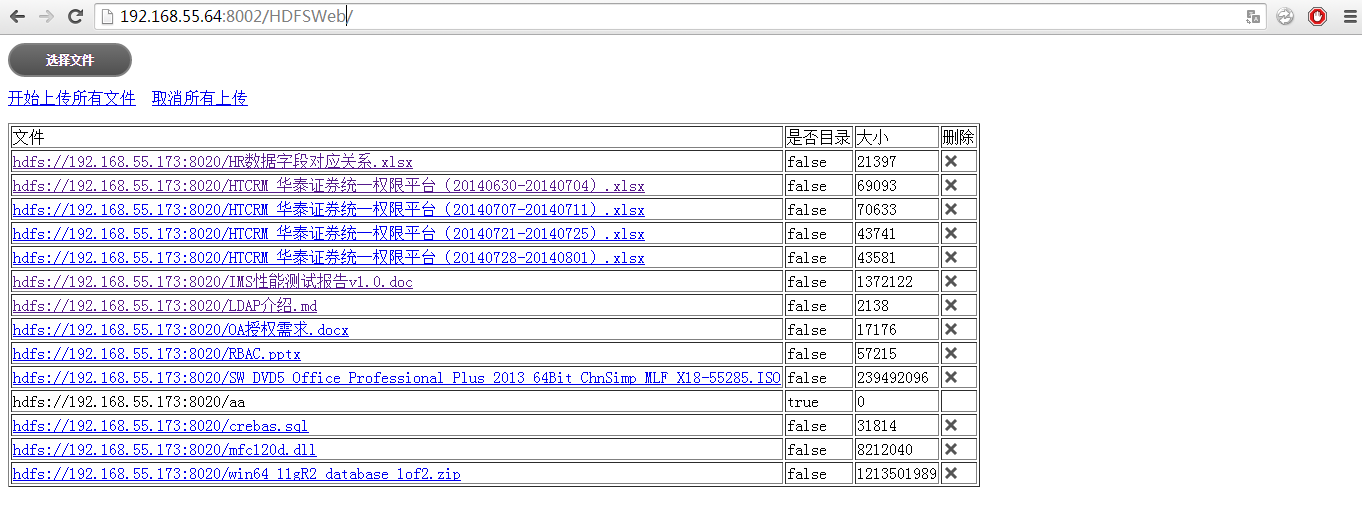
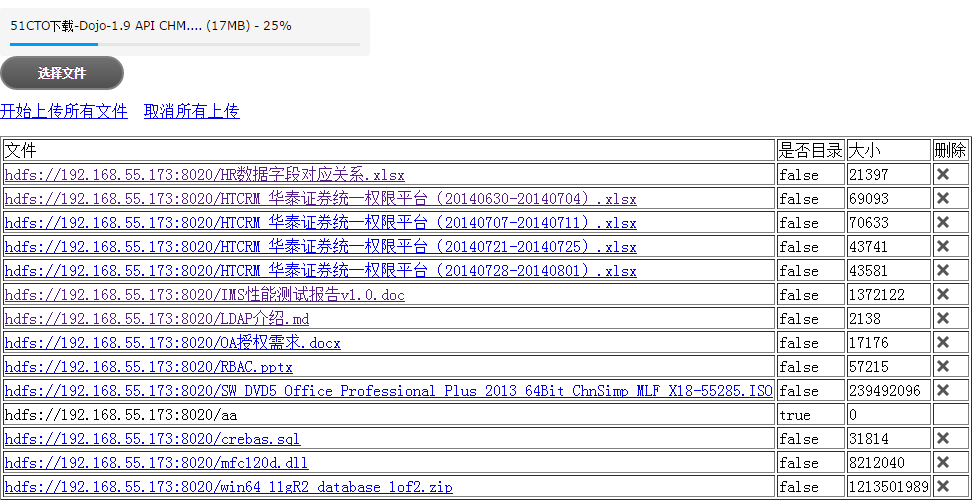
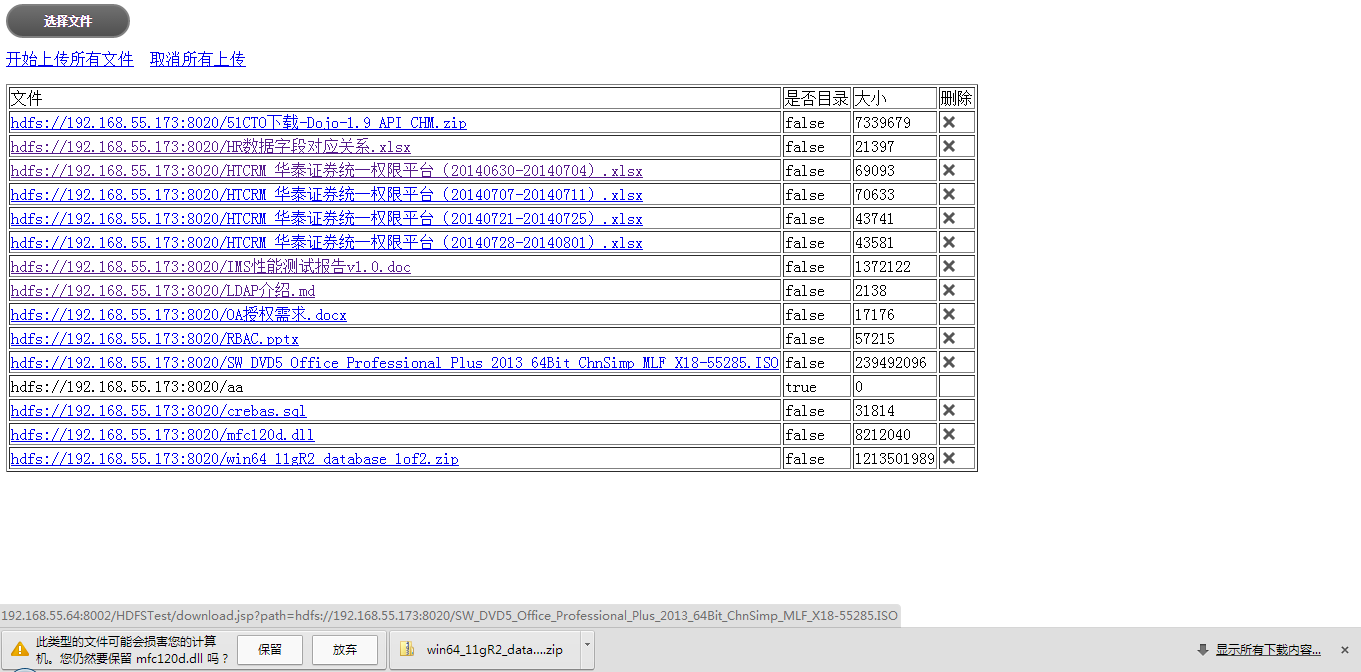
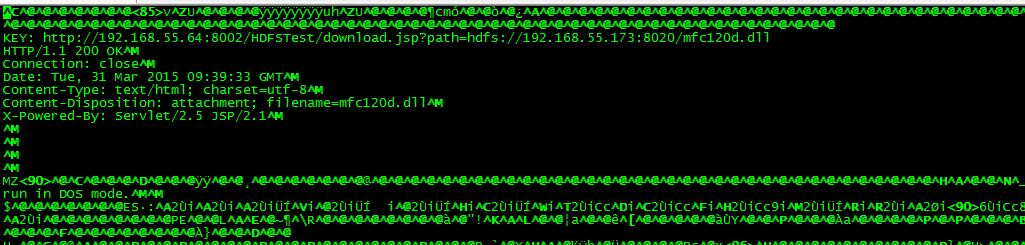
点击文件下载

下载完成查看缓存目录
$ cd /home/cache查看缓存文件
-rw-------. 1 nobody nobody 8212493 Mar 31 17:27 91aa96dab8d300dc81295f78552a4a0a
POC过程中的疑问
- Hadoop是否适合做分布式文件服务器?
作为分布式文件系统,hadoop默认的文件存储块大小为64M,而对于作为文件服务器存放小文件,会极大浪费系统资源。如果调整默认存储块大小,那么对于其它基于hadoop服务的应用会不会受到影响。 - 作为分布式文件服务器性能测试。
性能测试尚未完成。