硬件准备
| 机器名 | IP | 硬件配置 | 操作系统 |
|---|---|---|---|
| nimbus | 192.168.55.173 | 4cpu 2.93GHz 4G内存 | Linux x86_64 |
| supervisor1 | 192.168.55.174 | 4cpu 2.93GHz 4G内存 | Linux x86_64 |
| supervisor2 | 192.168.55.175 | 4cpu 2.93GHz 4G内存 | Linux x86_64 |
软件准备
三台虚拟机,一台作为
Hadoop的namenode,另外两台做Hadoop的datanode。
基本软件安装
三台机器必备安装软件,jdk、hadoop
Jdk1.7.0_15安装
下载JDK
$ wget http://download.oracle.com/otn-pub/java/jdk/8u31-b13/jdk-7u15-linux-x64.tar.gz解压JDK
tar zvxf jdk-7u15-linux-x64.tar.gz设置环境变量
$ set PATH=/your_jdk_unzip_dir/jdk1.7.0_15/bin:$PATH $ set JAVA_HOME=/your_jdk_unzip_dir/jdk1.7.0_15验证Jdk版本
$ jdk -version
Hadoop2.6.0安装
下载Hadoop
$ wget http://apache.fayea.com/hadoop/common/stable/hadoop-2.6.0.tar.gz切换root用户添加Hadoop用户
$ groupadd hadoop $ useradd hadoop hadoop $ passwd hadoop #为用户添加密码 可以不设置密码安装ssh
$ rpm -qa |grep ssh #检查是否装了SSH包 $ yum install openssh-server # 安装ssh $ chkconfig --list sshd #检查SSHD是否设置为开机启动 $ chkconfig --level 2345 sshd on #如果没设置启动就设置下. $ service sshd restart #重新启动配置ssh无密码登录
nimbus$ ssh-keygen -t rsa nimbus$ ssh-copy-id hadoop@nimbus nimbus$ ssh-copy-id hadoop@supervisor1 nimbus$ ssh-copy-id hadoop@supervisor2然后用scp命令,把公钥文件发放给slaver
nimbus$ scp .ssh/id_rsa.pub hadoop@supervisor1:/home/hadoop/id_rsa_01.pub nimbus$ scp .ssh/id_rsa.pub hadoop@supervisor2:/home/hadoop/id_rsa_01.pub测试无密码登录
$ ssh nimbus $ ssh supervisor1 $ ssh supervisor2安装hadoop
$ tar vxzf hadoop-2.6.0.tar.gz修改hadoop配置文件
slaves$vi etc/hadoop/slaves supervisor1 supervisor2core-site.xml
$vi etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://nimbus:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/app/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.u0.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.u0.groups</name> <value>*</value> </property> </configuration>hdfs-site.xml
$vi etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>nimbus:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/app/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/app/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>mapred-site.xml
$vi etc/hadoop/mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>nimbus:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>nimbus:19888</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>同步hadoop目录到supervisor和supervisor2
$ scp hadoop/* -R hadoop@supervisor1:/app/hadoop/ $ scp hadoop/* -R hadoop@supervisor2:/app/hadoop/启动hadoop
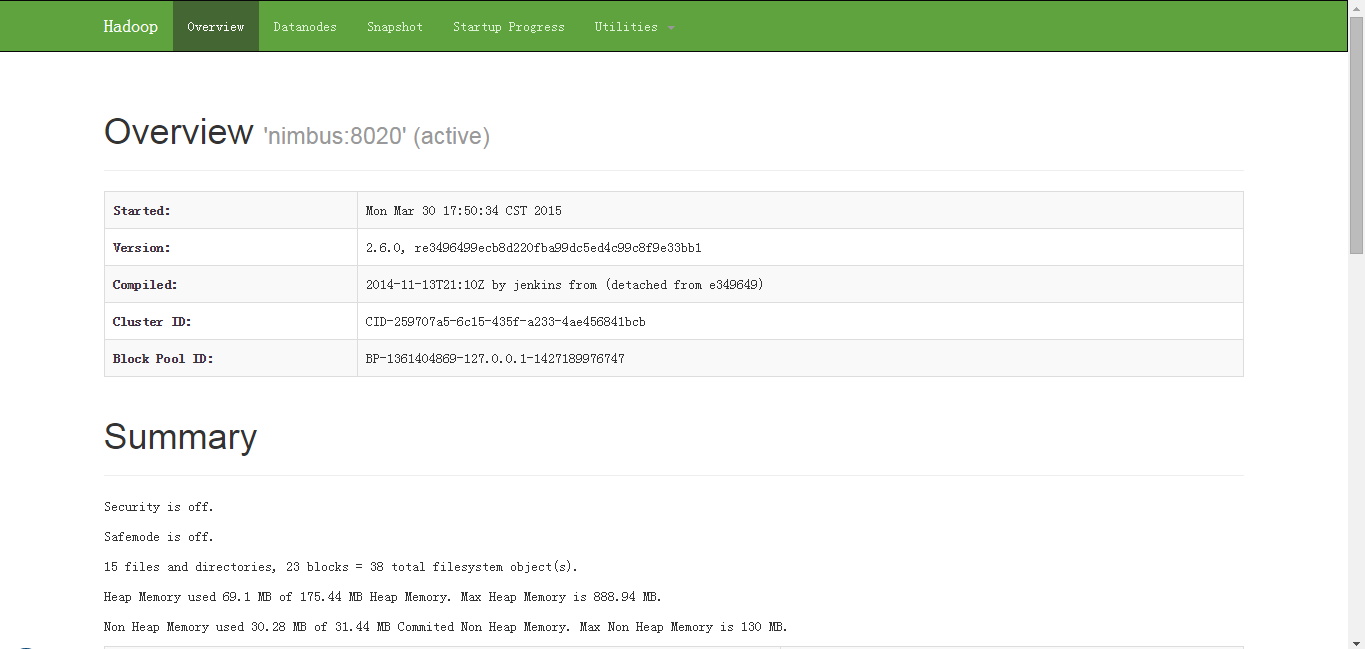
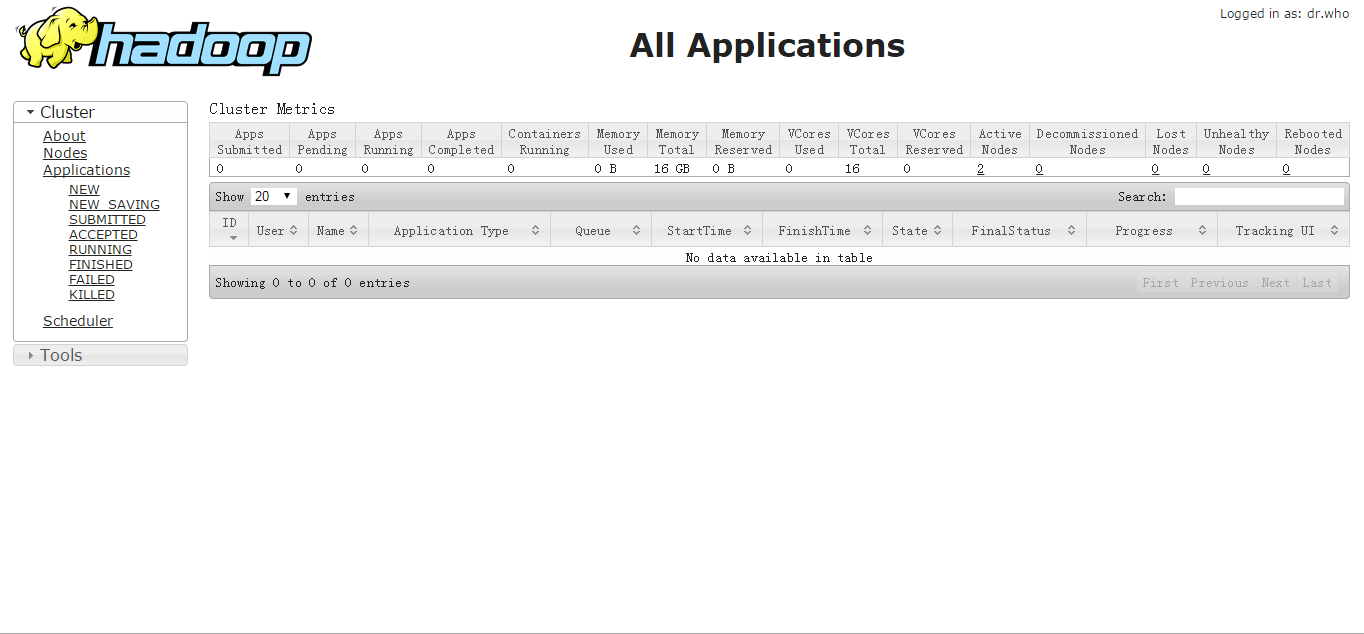
$ ./sbin/start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 15/03/30 17:50:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [nimbus] nimbus: starting namenode, logging to /app/hadoop/logs/hadoop-hadoop-namenode-nimbus.out supervisor2: starting datanode, logging to /app/hadoop/logs/hadoop-hadoop-datanode-supervisor2.out supervisor1: starting datanode, logging to /app/hadoop/logs/hadoop-hadoop-datanode-supervisor1.out Starting secondary namenodes [nimbus] nimbus: starting secondarynamenode, logging to /app/hadoop/logs/hadoop-hadoop-secondarynamenode-nimbus.out 15/03/30 17:50:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable starting yarn daemons starting resourcemanager, logging to /app/hadoop/logs/yarn-hadoop-resourcemanager-nimbus.out supervisor2: starting nodemanager, logging to /app/hadoop/logs/yarn-hadoop-nodemanager-supervisor2.out supervisor1: starting nodemanager, logging to /app/hadoop/logs/yarn-hadoop-nodemanager-supervisor1.out查看进程
nimbus$ jps 10775 Jps 10146 NameNode 10305 SecondaryNameNode 10464 ResourceManager supervisor1$ jps 4308 Jps 4094 NodeManager 3993 DataNode supervisor2$ jps 4308 Jps 4094 NodeManager 3993 DataNode查看管理页面