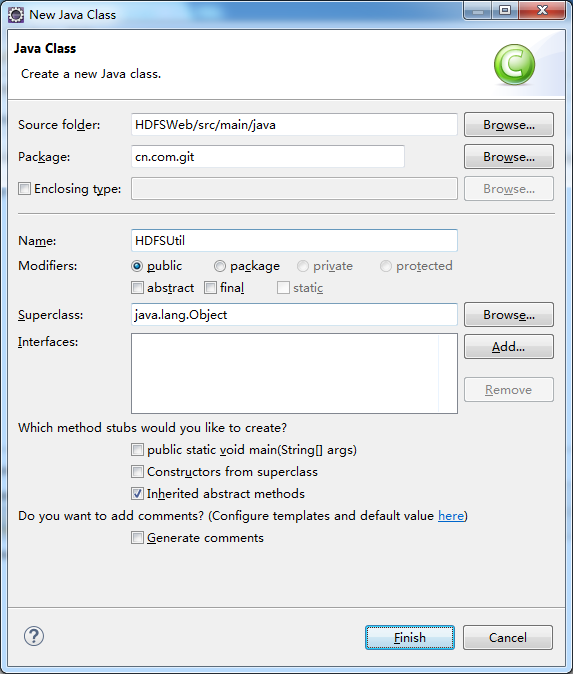
CI服务器
CI服务器,持续集成服务器,通过自动化的构建来验证,包括自动编译、发布和测试,从而尽快地发现集成错误,让团队能够更快的开发内聚的软件。本文搭建基于 Docker+Jenkis+Sonar+Nexus 的CI服务器。
环境准备
Docker环境准备(略),确信docker服务已安装并且docker命令可执行。
sudo docker
Nexus安装
1.安装
sudo docker search nexus
找到sonatype/nexus
sonatype/nexus Sonatype Nexus 51 [OK]
sudo docker pull sonatype/nexus
下载image完成后,启动nexus
sudo docker run -d -p 8081:8081 --name sonatype-nexus -v /app/nexus-data/sonatype-work:/sonatype-work sonatype/nexus:oss
映射容器8081端口和数据存放目录/sonatype-work 到宿主机器上。
2.配置
访问 http://nexus:8081 默认管理员账号admin/admin123登录。

Jenkins安装
1.安装
sudo docker search jenkins
找到官方image
jenkins Official Jenkins Docker image 553 [OK]
sudo docker pull jenkins
下载image完成后,启动jenkins
sudo docker run --name jenkins -d -u root -p 8080:8080 -v /app/jenkins_home:/var/jenkins_home jenkins
映射容器8080端口和数据存放目录/var/jenkins_home 到宿主机器上。
2.配置
访问 http://jenkins:8080